☆-虚拟DOM提高性能
虚拟
dom相当于在js和真实dom中间加了一个缓存,利用dom diff算法避免了没有必 要的dom操作,从而提高性能。用
JavaScript对象结构表示DOM树的结构;然后用这个树构建一个真正的DOM树,插到文档当中,当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异:把
2所记录的差异应用到步骤1所构建的真正的DOM树上,视图就更新了。
☆-Virtual DOM的优势在哪里
Virtual Dom 的优势
其实这道题目面试官更想听到的答案不是上来就说 直接操作/频繁操作DOM 的性能差,如果 DOM 操作的性能如此不堪,那么 jQuery 也不至于活到今天。
所以面试官更想听到 VDOM 想解决的问题,以及为什么频繁的 DOM 操作会性能差。
首先我们需要知道:
DOM渲染引擎、JS引擎 相互独立,但又工作在同一线程(主线程)JS代码调用DOM API时,必须挂起JS引擎,转换传入参数数据、激活DOM渲染引擎,DOM重绘后再转换可能有的返回值,最后激活JS引擎并继续执行- 若有频繁的
DOM API调用,且浏览器厂商不做“批量处理”优化, 引擎间切换的单位代价将迅速积累 - 若其中有强制重绘的
DOM API调用,重新计算布局、重新绘制图像会引起更大的性能消耗。
其次,VDOM 和真实 DOM 的区别和优化:
- 虚拟
DOM不会立马进行排版与重绘操作 - 虚拟
DOM进行频繁修改,然后一次性比较并修改真实DOM中需要改的部分, - 最后在真实
DOM中进行排版与重绘,减少过多DOM节点排版与重绘损耗 - 虚拟
DOM有效降低大面积真实DOM的重绘与排版,因为最终与真实DOM比较差异,可以只渲染局部
☆-URL和URI的区别
URI: Uniform Resource Identifier 指的是统一资源标识符
URL: Uniform Resource Location 指的是统一资源定位符
URI 指的是统一资源标识符,用唯一的标识来确定一个资源,它是一种抽象的定义,也就是说,不管使用什么方法来定义,只要能唯一的标识一个资源,就可以称为 URI。
URL 指的是统一资源定位符,URN指的是统一资源名称。URL 和 URN 是 URI 的子集,URL 可以理解为使用地址来标识资源。
☆-如何实现图片懒加载
懒加载也叫延迟加载,指的是在长网页中延迟加载图片的时机,当用户需要访问时,再去加载,这样可以提高网站的首屏加载速度,提升用户的体验,并且可以减少服务器的压力。
它适用于图片很多,页面很长的电商网站的场景。
懒加载的实现原理是,将页面上的图片的 src 属性设置为空字符串,将图片的真实路径保存在一个自定义属性中,当页面滚动的时候,进行判断,如果图片进入页面可视区域内,则从自定义属性中取出真实路径赋值给图片的 src 属性,以此来实现图片的延迟加载。
☆-优雅降级和渐进增强
渐进增强( progressive enhancement):针对低版本浏览器进行构建页面,保证最基本的功能,
然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验。
优雅降级(graceful degradation) :一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
区别:
- (1) 优雅降级是从复杂的现状开始,并试图减少用户体验的供给
- (2) 渐进增强则是从一个非常基础的,能够起作用的版本开始,并不断扩充,以适应未来环境的需要
function foo(){//code... }()定义预格式文本,保持文本原有的格式 - (3) 降级(功能衰减)意味着往回看;而渐进增强则意味着朝前看,同时保证其根基处于安全地带
☆-前端需要注意哪些SEO
- (1)合理的
title、description、keywords:搜索对着三项的权重逐个减小,title值强调重点即可,重要关键词出现不要超过2次,而且要靠前,不同页面title要有所不同;description把页面内容高度 概括,长度合适,不可过分堆砌关键词,不同页面description有所不同;keywords列举出重要 关键词即可。
- (2)语义化的
HTML代码,符合W3C规范:语义化代码让搜索引擎容易理解网页。 - (3)重要内容
HTML代码放在最前:搜索引擎抓取HTML顺序是从上到下,有的搜索引擎对抓取长度有限制,保证重要内容肯定被抓取。 - (4)重要内容不要用
js输出:爬虫不会执行js获取内容 - (5)少用
iframe:搜索引擎不会抓取iframe中的内容 - (6)非装饰性图片必须加
alt - (7)提高网站速度:网站速度是搜索引擎排序的一个重要指标
☆-首屏和白屏时间如何计算
首屏时间的计算,可以由 Native WebView 提供的类似 onload 的方法实现,在 ios 下对应的是
webViewDidFinishLoad,在 android 下对应的是onPageFinished事件。
白屏的定义有多种。可以认为“没有任何内容”是白屏,可以认为“网络或服务异常”是白屏,可以认为“数据加载中”是白 屏,可以认为“图片加载不出来”是白屏。
场景不同,白屏的计算方式就不相同。
- 方法1:当页面的元素数小于
x时,则认为页面白屏。比如“没有任何内容”,可以获取页面的DOM节点数,判断DOM节点数少于某个阈值X,则认为白屏。 - 方法2:当页面出现业务定义的错误码时,则认为是白屏。比如“网络或服务异常”。
- 方法3:当页面出现业务定义的特征值时,则认为是白屏。比如“数据加载中”。
☆-Cookie的作用和弊端
cookie作用
1.可以在客户端上保存用户数据,起到简单的缓存和用户身份识别等作用。
2.保存用户的登陆状态,用户进行登陆,成功登陆后,服务器生成特定的cookie返回给客户端,客户端下次访问该域名下的任何页面,将该cookie的信息发送给服务器,服务器经过检验,来判断用户是否登陆。
3.记录用户的行为。
cookie弊端
- 1.增加流量消耗,每次请求都需要带上
cookie信息。 - 2.安全性隐患,
cookie使用明文传输。如果cookie被人拦截了,那人就可以取得所有的session信息。 - 3.
Cookie数量和长度的限制。每个domain最多只能有20条cookie,每个cookie长度不能超过4KB,否则会被截掉。 - 4.缺乏数据操作接口,浏览器端获取和设置
cookie只能通过document.cookie实现。
♥-浏览器输入url到页面呈现出来的过程
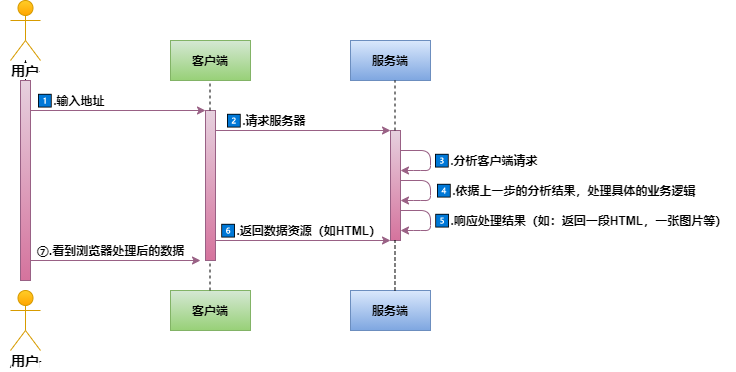
1、输入
url后,首先需要找到这个url域名的服务器ip,- ip 查找过程:缓存 -> hosts -> DNS
- 为了寻找这个 ip ,浏览器首先会寻找 缓存,查看缓存中是否有记录,缓存的查找记录为:浏览器缓存 -》 系统缓存 -》 路由器缓存,
- 缓存中没有则查找系统的 hosts 文件中是否有记录,
- 如果没有则查询 DNS 服务器,
- ip 查找过程:缓存 -> hosts -> DNS
2、得到服务器的
ip地址后,浏览器根据这个ip以及相应的端口号,构造一个http请求,- 这个请求报文会包括这次请求的信息,
- 主要是请求方法,请求说明和请求附带的数据,
- 并将这个 http 请求封装在一个 tcp 包中,
- 这个 tcp 包会依次经过传输层,网络层,数据链路层,物理层到达服务器,
- 这个请求报文会包括这次请求的信息,
3、服务器解析这个请求来作出响应,返回相应的
html给浏览器,- 分析客户端请求
- 根据分析结果处理业务逻辑
- 响应处理结果,如返回相应的html
4、因为
html是一个树形结构,浏览器根据这个html来构建DOM树,- 在 dom 树的构建过程中如果遇到 JS 脚本和外部 JS 连接,则会停止构建 DOM 树来执行和下载相应的代码,这会造成阻塞,
- 这就是为什么推荐 JS 代码应该放在 html 代码的后面,
5、之后根据外部样式,内部样式,内联样式构建一个
CSS对象模型树CSSOM树,构建完成后和DOM树合并为渲染树,- 这里主要做的是排除非视觉节点,比如 script, meta 标签和排除 display 为 none 的节点,之后进行布局,
- 布局主要是确定各个元素的位置和尺寸,
6、之后是渲染页面,
- 因为 html 文件中会含有图片,视频,音频等资源,
- 在解析 DOM 的过程中,遇到这些都会进行并行下载,
- 浏览器对每个域的并行下载数量有一定的限制,一般是 4-6 个,
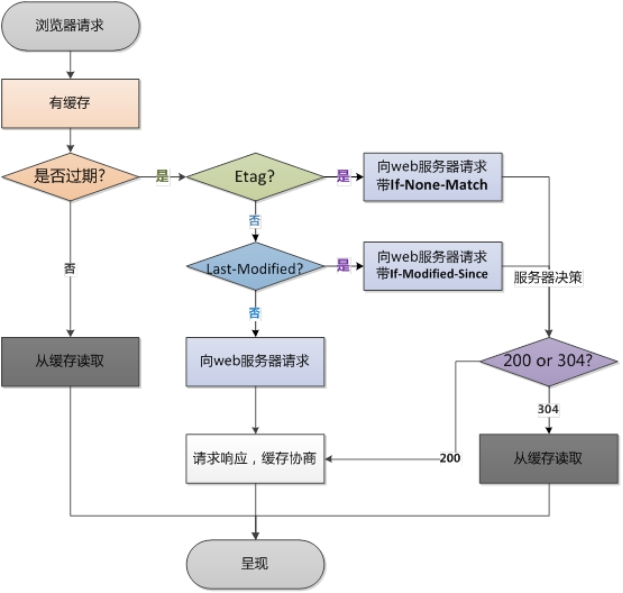
7、当然在这些所有的请求中我们还需要关注的就是缓存,缓存一般通过
Cache-Control、Last-Modify、Expires等首部字段控制。- Cache-Control 和 Expires 的区别在于
- Cache-Control 使用相对时间,
- Expires 使用的是基于服务器端的绝对时间,
- 因为存在时差问题,一般采用 Cache-Control,
- Cache-Control 和 Expires 的区别在于
8、在请求这些有设置了缓存的数据时,会先查看是否过期,
如果没有过期则直接使用本地缓存,
过期则请求并在服务器校验文件是否修改,
- 如果上一次响应设置了 ETag 值,会在这次请求的时候作为 If-None-Match 的值交给服务器校验,
- 如果一致,继续校验 Last-Modified,没有设置 ETag 则直接验证 Last-Modified,再决定是否返回 304